slash-trombone.github.io
Pink trombone audios
Authors: Mateo Cámara, Zhiyuan Xu, Yisu Zong, and David Südholt.
Abstract: We present a systematic methodology to evaluate the synthesis capability of a simplified model of the vocal tract on non-speech human sounds. The Pink Trombone (PT) model, known for its simplicity and efficiency, is used as a case study. Yawning sounds are used as the non-speech signal of interest. We estimate the control parameters to minimize the difference between real and generated audio. The articulatory parameters are optimized using three strategies: genetic models, neural networks, and derivative-free approximations. We also validated several popular quality metrics as error objective functions. We compared the results in terms of error committed and computational demand. The insights can serve as a benchmark to validate other physical models and signal types.
Data: You can take this website as a preview of some of the examples we mention in the paper. Six methods have been applied to regenerate human sounds, while each of them has tried 4 different representation of sounds. If you are interested in all the regenerated audio samples, you can find it here. And if you are looking for the Pink Trombone generated dataset to train neural network, you can find it here.
Pink Trombone audios without variation (4.1)
All methods perform very well in predicting articulatory parameters, the result is shown in the table below. Since the performance of each method can be objectively computed, we only take a few examples as an example.
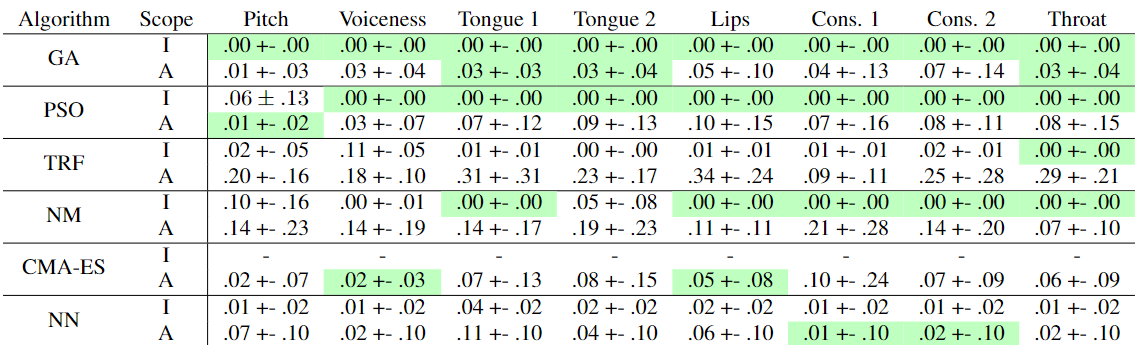
original 1: regenerated 1:
original 2: regenerated 2:
Pink Trombone audios without variation with Gaussian Noise (4.1)
In this part, different amounts of Gaussian white noise were added to the original signal, and we regenerated Pink Trombone audios with the predicted articulatory parameters that defined the signal. PLEASE MIND THE VOLUME, IT COULD BE VERY LOUD
| 40dB | 20dB | 0dB | -10dB | |
|---|---|---|---|---|
| original | ||||
| GA_mel | ||||
| GA_mfcc | ||||
| GA_stft | ||||
| GA_multiscale | ||||
| PSO_mel | ||||
| PSO_mfcc | ||||
| PSO_stft | ||||
| PSO_multiscale | ||||
| TRF_mel | ||||
| TRF_mfcc | ||||
| TRF_stft | ||||
| TRF_multiscale | ||||
| NM_mel | ||||
| NM_mfcc | ||||
| NM_stft | ||||
| NM_multiscale | ||||
| CMA-ES_mel | ||||
| CMA-ES_mfcc | ||||
| CMA-ES_stft | ||||
| CMA-ES_multiscale | ||||
| NN_mel | ||||
| NN_mfcc | ||||
| NN_stft | ||||
| NN_multiscale |
Pink Trombone audios with variation (4.2)
We have tried several perceptual metrics (PESQ, PEAQ, ViSQOL, WARP-Q and STOI) to find out how similar the sounds generated by the synthesizer were to human-generated ones. You can find out the result of each perceptual metric in Table 3 in our paper. But you are very welcome and encouraged to evaluate quality by yourself, and that’s why this site exists.
| vowel /a/ | vowel /o/ | yawn 1 | |
|---|---|---|---|
| original | |||
| GA_mel | |||
| GA_mfcc | |||
| GA_stft | |||
| GA_multiscale | |||
| PSO_mel | |||
| PSO_mfcc | |||
| PSO_stft | |||
| PSO_multiscale | |||
| TRF_mel | |||
| TRF_mfcc | |||
| TRF_stft | |||
| TRF_multiscale | |||
| NM_mel | |||
| NM_mfcc | |||
| NM_stft | |||
| NM_multiscale | |||
| CMA-ES_mel | |||
| CMA-ES_mfcc | |||
| CMA-ES_stft | |||
| CMA-ES_multiscale | |||
| NN_mel | |||
| NN_mfcc | |||
| NN_stft | |||
| NN_multiscale |
Some Interesting trials
Trial One
Based on the outputs of optimization, which are the values of each control parameter, we not only fed it back to Pink Trombone to generate audio, GIF files are also generated to see how each part of vocal tract moves.
For example, the GIF file of a yawn is shown below. (Movements have been slown down to catch details)
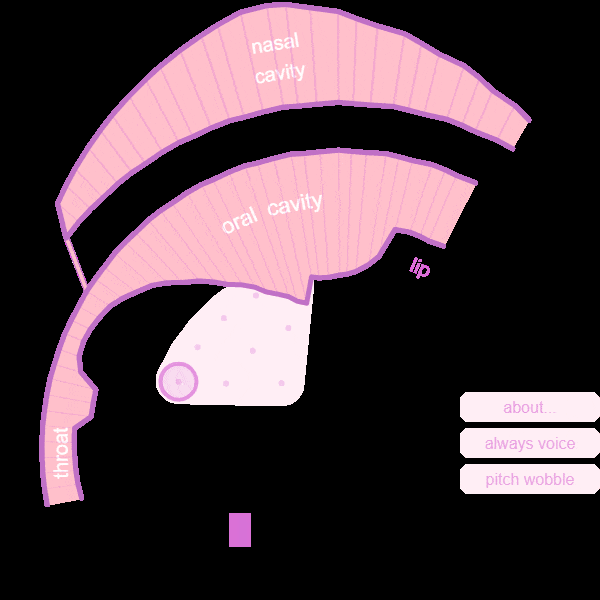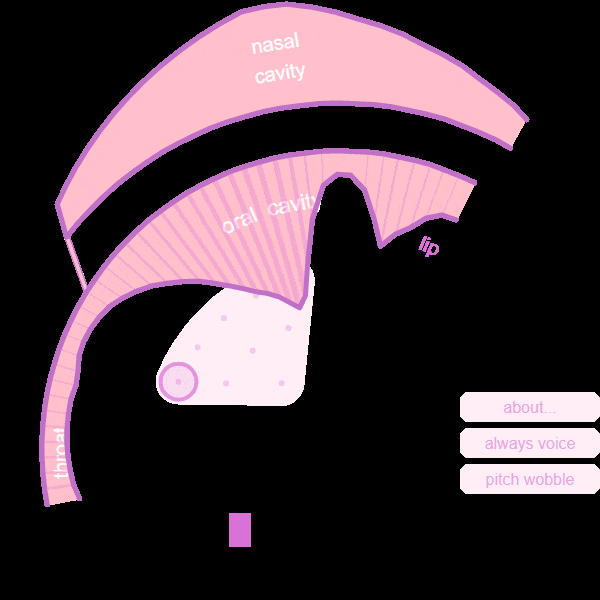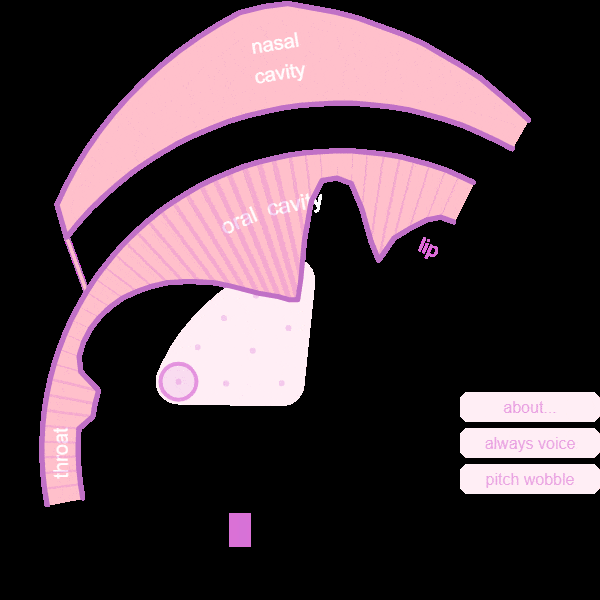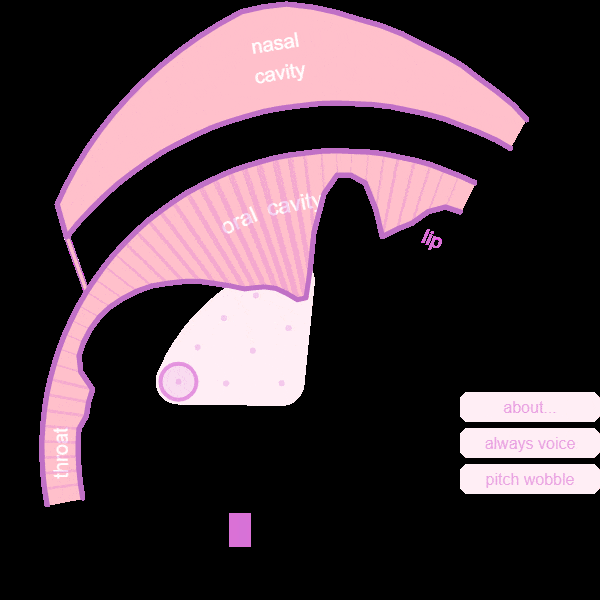
Trial Two
We tried NN_stft on regenerating a Chinese song which was popular on TikTok.
Original version: Regenerated version: